Shannon-Fano-Elias coding and Arithmetic Coding
Shanon-Fano-Elias coding
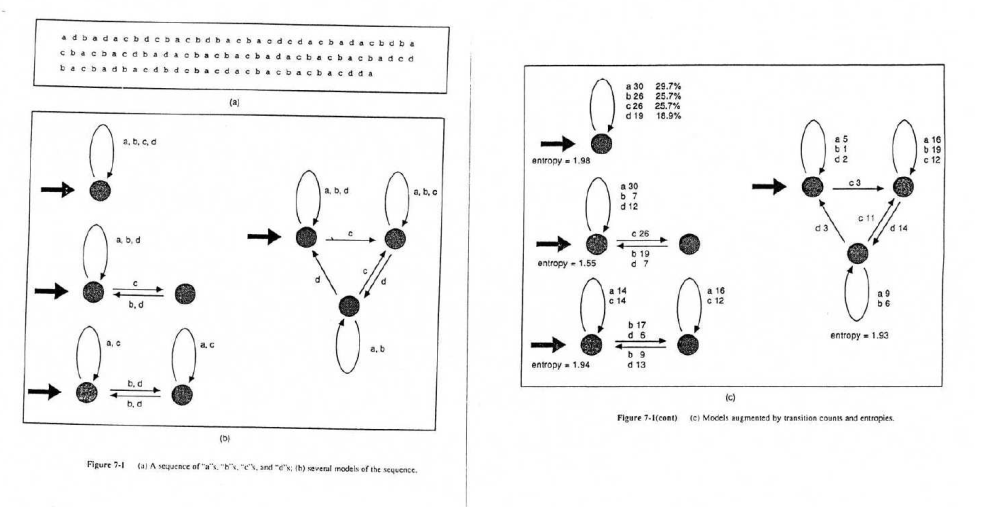
Knowing the symbols probabilities, SFE codes a truncated binary representation the cumulative distribution function. (and not proba directly because can have same value).
Probabilities for symbols are:
Cumulative distribution function
We can introduce:
It corresponds to the middle point of a step in the distribition plot.
For a given , it is possible to retrieve . (see figure)
We use this value because it’s also possible to retieve with an
approximation of .
What precision do we need to retrieve ?
Let’s truncate by bits (denoted by )
Then by definition of truncation to bits:
Lets chose
Then:
Hence this value of ensures
Is this code of prefix?
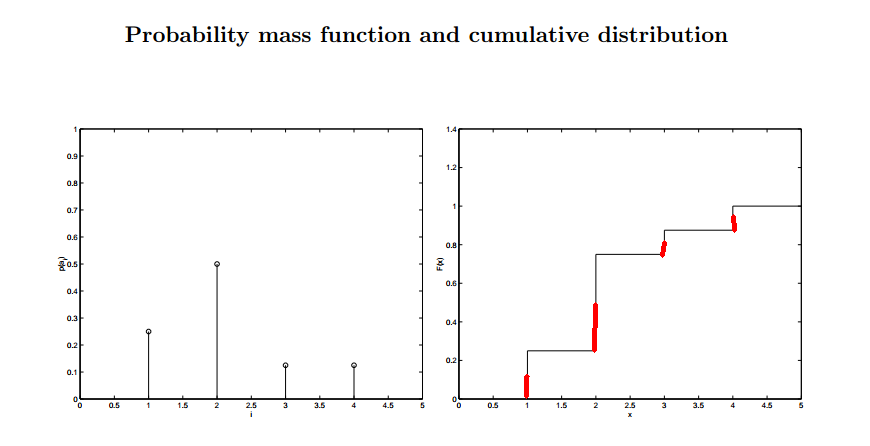
Let the codeword represent
Any number outside this interval has at least a bit between 1 and $l$ that changes –> not a prefix of a codeword of another interval.
In the case of the SFE, all intervals are separated (see figure) so it is prefix.
Example

Performance
Codeword length:
The performance can be improved by coding several symbols in each codeword.
This leads to arithmetic coding.
Arithmetic coding
Principle
Arithmetic coding is a generalization of the SFE.
Its aim is to code a sequence on the fly knowing the
probabilities of the symbols.
Let be the cumulative probabilty distribution. We want to compute it
at each step, in order to finally have the unique:
The final codeword will be in this interval.
The principle to determining the interval is the following:
- divide the interval proportionally to the primary cumulative distribution, to each interval its corresponding symbol is associated.
- chose subinterval of symbol to be coded. This new interval is itself divided in subinterval with respect to the primary probability distribution.
- proceed until the sequence is over.
Total probability: = product of probabilities of each character = is the size of the interval.
Hence at the end the codeword is:
with:
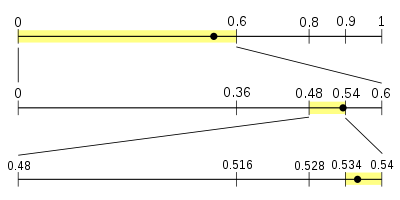
Remark: in order to decode, only need to follow the path given by the intervals to find value.
Benefits
Huffman can only come close to by using large block of code. Which means
you need a pre-designed codebook of exponentially growing size (huffmantree).
On the opposite, AC enables coding large blocks w/o having to know codewords a priori –> generate code for entire sequence directly.
Furthermore it has the ability to be adaptable.
Adaptative models for arithmetic coding
During the processing of a sequence, given the information we already have, we can use predictive models to define the probability of the current symbol.
Example for text:
Given the previous seen text, we can find the probality for a symbol to be the next letter:
Type of models
According to flexibility
- static
- semistatic
- adaptive
According to quantity of preceding text taken into account
- finite context model of order : m previous symbols used to make prediction (size of the word).
For instance, prediction by partial matching (PPM) uses finite context models, for each symbol, context starts at n:- decrease order:
- if unseen context: decrease
- if seen context but unseen encoded char after it: escape symbol
- else: use probability
Finally the char will have all the escapes probs + prob of char.
If no context for this char use simple model of equiprobabilty.
- decrease order:
-
finite state models: the probabilities are obtained by modelling the best finite state machines representing the sequence. Each transition has a probability associated with it.